Travel Tips
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
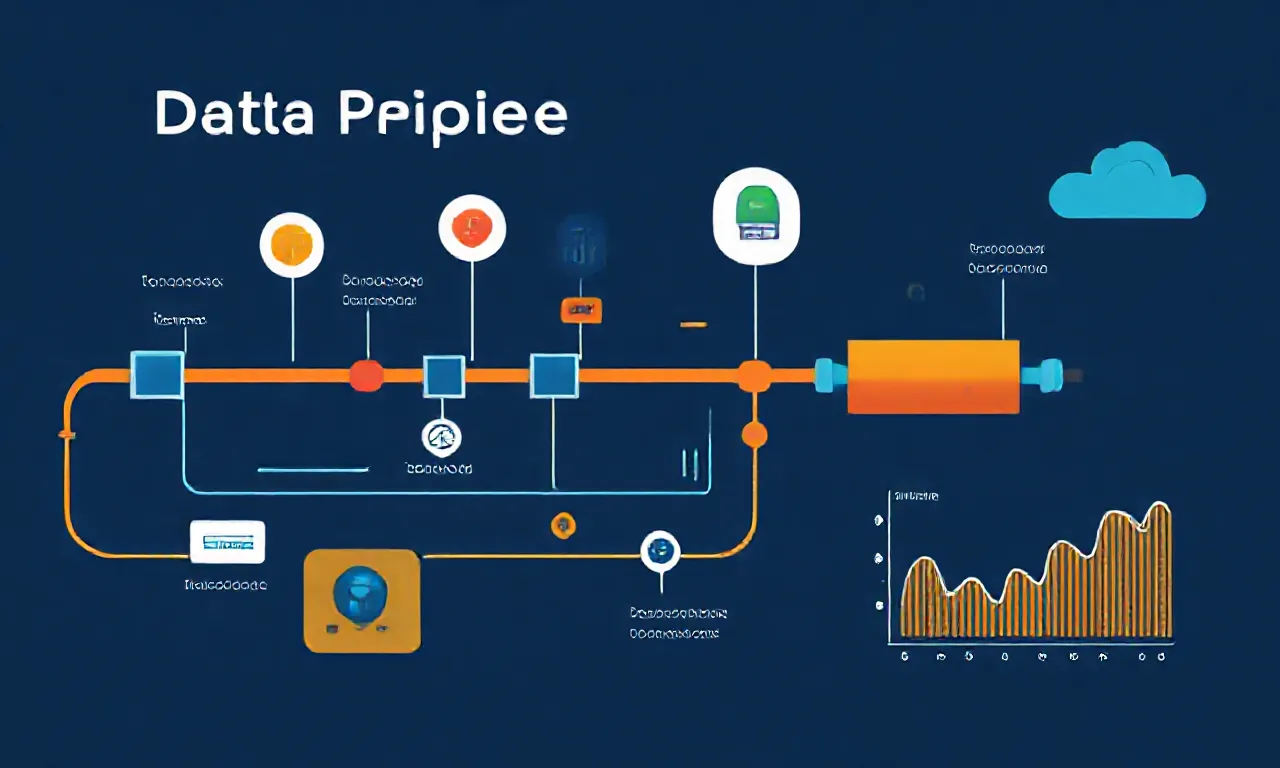
Entenda a importância dos Data Pipelines na gestão de dados modernos.
Os Data Pipelines são estruturas essenciais na arquitetura de dados moderna, permitindo a movimentação e transformação de dados de forma automatizada. Eles consistem em um conjunto de ferramentas e processos que facilitam a coleta, processamento e armazenamento de dados, garantindo que a informação certa chegue ao lugar certo no momento certo. Com o crescimento exponencial da quantidade de dados gerados, a automação do fluxo de dados se torna crucial para a tomada de decisões baseadas em dados.
Um Data Pipeline pode ser dividido em várias etapas. A primeira delas é a extração de dados, que pode vir de diversas fontes, como bancos de dados, APIs, arquivos CSV, entre outros. Essa diversidade de fontes é uma das características que torna os Data Pipelines tão valiosos, pois eles podem integrar dados de diferentes sistemas e formatos.
Após a extração, os dados frequentemente precisam ser limpos e transformados para garantir a sua qualidade e relevância. Essa etapa de transformação pode incluir a normalização de dados, a remoção de duplicatas e a aplicação de regras de negócios.
Após a transformação, os dados são carregados em um sistema de armazenamento, que pode ser um data warehouse ou um data lake, dependendo das necessidades da organização.
O uso de data warehouses é comum em empresas que precisam de análises rápidas e relatórios, enquanto os data lakes são mais adequados para armazenar grandes volumes de dados não estruturados. A escolha entre um ou outro depende do tipo de análise que será realizada e da natureza dos dados.
Uma das principais vantagens dos Data Pipelines é a automação.
Com a automação, as organizações podem reduzir erros manuais, aumentar a eficiência e garantir que os dados estejam sempre atualizados. Ferramentas de orquestração de dados, como Apache Airflow ou Luigi, permitem que os fluxos de trabalho sejam programados e monitorados, facilitando a gestão do pipeline. Essa automação não apenas economiza tempo, mas também permite que as equipes se concentrem em tarefas mais estratégicas, em vez de se perderem em processos manuais.
Além disso, Data Pipelines são fundamentais para a implementação de práticas de análise preditiva e machine learning. Esses modelos dependem de dados limpos e bem estruturados para gerar insights significativos. Com um pipeline de dados eficiente, as organizações podem alimentar modelos de machine learning com dados em tempo real, permitindo que as análises sejam mais precisas e relevantes.
Outro aspecto importante é a escalabilidade dos Data Pipelines. À medida que as organizações crescem e a quantidade de dados aumenta, é crucial que os pipelines possam se adaptar a essas mudanças. Soluções em nuvem, como AWS Glue ou Google Cloud Dataflow, oferecem a flexibilidade necessária para escalar pipelines conforme a demanda, garantindo que as operações não sejam comprometidas.
A segurança dos dados também é uma preocupação fundamental em qualquer Data Pipeline. Implementar medidas de segurança, como criptografia e controle de acesso, é essencial para proteger informações sensíveis durante todo o processo de movimentação de dados. Além disso, as organizações devem estar atentas às regulamentações de proteção de dados, como o GDPR, que exigem práticas rigorosas de governança de dados.
Por fim, a visualização e o monitoramento dos Data Pipelines são cruciais para garantir seu funcionamento adequado. Ferramentas de monitoramento permitem que as equipes identifiquem rapidamente gargalos ou falhas no processo, garantindo que as operações de dados sejam contínuas e confiáveis. A capacidade de visualizar o fluxo de dados em tempo real ajuda as organizações a manterem a eficiência e a qualidade dos dados, elementos essenciais para uma tomada de decisão informada.